Ph.D. Candidate: Mustafa Erolcan Er
Program: Cognitive Science
Date: 23.12.2025 / 15:00
Place: A-212
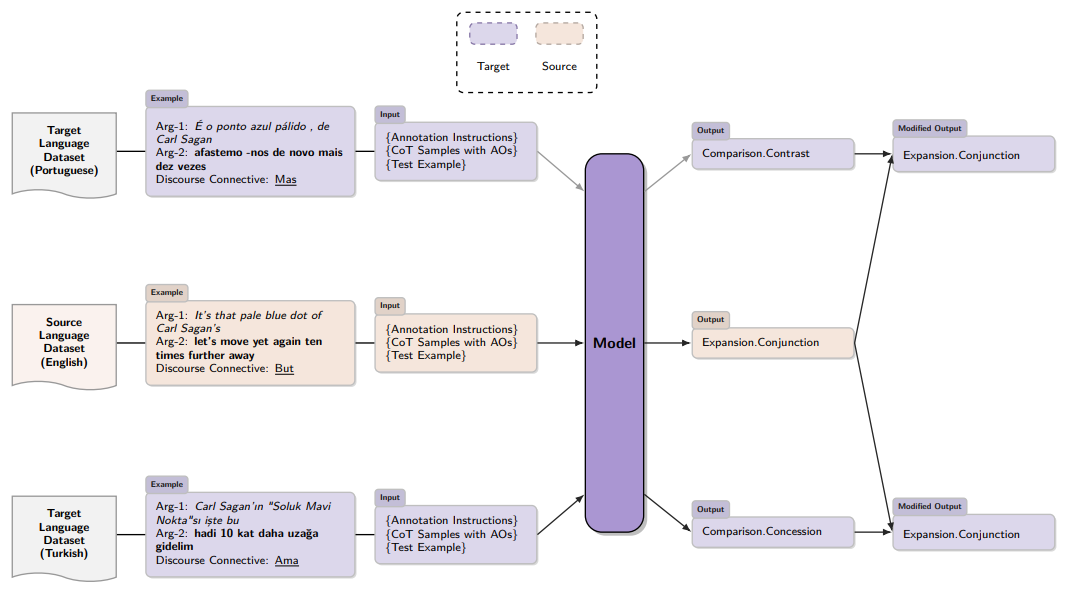
Abstract: Discourse parsing is one of the most challenging tasks in the field of Natural Language Processing (NLP) due to its inherent complexity. However, advancements in large language model techniques have begun to demonstrate remarkable influence on discourse parsing, as they have across all areas of NLP. In this thesis, we introduce a multilingual discourse parsing framework designed for the Penn Discourse TreeBank (PDTB)-based datasets. Discourse parsing models based on the PDTB ideally involve three modules: discourse connective (DC) detection, argument span labeling, and discourse relation recognition (DRR). We first perform the DC detection and argument span labeling tasks for Explicit and Alternative Lexicalization (AltLex) relation types by fine-tuning the BERT model. Then, we perform the DRR phase (Explicit, Implicit and AltLex relation types) using various in-context learning strategies. Finally, we define two interconnected modules, one connecting the DC detection module with the argument span labeling module, and the other connecting DC detection module with the DRR. These modules can be considered as a first step toward end-to-end discourse parsing. Our discourse parsing pipeline is tested on seven different datasets across three languages (English, Portuguese, and Turkish) and achieves competitive results at each stage, on a par with the state-of-the-art discourse parsing models. In addition to our modular discourse parsing pipeline, we present two contributions: we propose a lightweight DC detection model and an improvement over the implicit DRR task by leveraging machine translation techniques.