


Announcements
Research News
Sürekli üretim ortamları büyük hacimli çok değişkenli sensör verisi üretse de, dil ve görüyü dönüştüren temel modellere sahip değildir ve “Dar Yapay Zekaya” sıkışmış durumdadır. Bu tez, bir tesisin sensörlerini dil gibi okuyan ve birbirine bağlı fiziğini öz-denetimli “Dört-Öğretmenli” geometrik maskelemeyle öğrenen, 1,6M parametreli kompakt ve çift yönlü bir Transformer kodlayıcı olan Prometheus’u tanıtır. Bir ham petrol damıtma ünitesinde Prometheus, 38 kanalın tamamında her metrikte üstün gelirken; ~300 kat daha büyük sıfır-örnekli Zaman Serisi Temel Modellerini geçer, tamamen eksik sensörleri yeniden inşa eder ve sahadaki yazılım-sensörün performansını aşar. Endüstriyel Temel Modellere giden yolun genel ölçeklemeden değil alana özelleşmeden geçtiğinin kanıtıdır.
Tarih: 25.06.2026 / 14:30 Yer: A-212

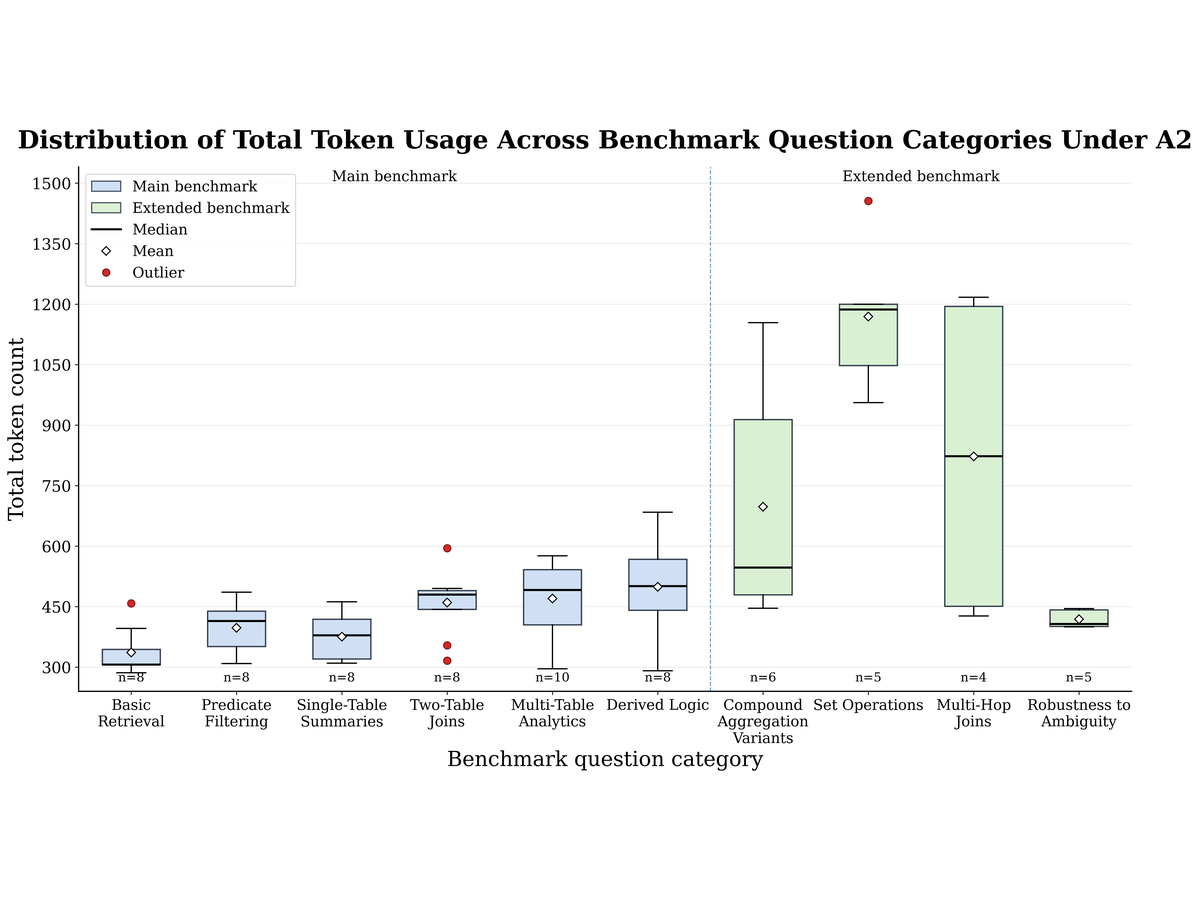
Bu tez, kullanıcıların karmaşık veri ortamlarını SQL yazmak yerine doğal dil ile sorgulayabilmesini sağlayan bir konuşma tabanlı analitik sistemi sunmaktadır. Sistem, lakehouse mimarisi üzerinde Veri Ağı (Data Mesh) ve Veri Dokusu (Data Fabric) ilkelerini birleştirmekte ve veri kümelerini keşfetmek, metadatayı zenginleştirmek ve tablolar arası ilişkileri çıkarsamak için LLM tabanlı ajanlar kullanmaktadır. Amaç, metadatanın şeffaf, yeniden kullanılabilir ve yeniden üretilebilir kalmasını sağlarken veri keşfi ve şema incelemesi için gereken manuel eforu azaltmaktır. Yaklaşım, ilişki metadatasının sorgu doğruluğu ve yeniden üretilebilirlik üzerindeki etkisini ölçmek için tasarlanmış çok alanlı bir kıyaslama üzerinden değerlendirilmiştir.
Tarih: 15.06.2026 / 15:00 Yer: A-212
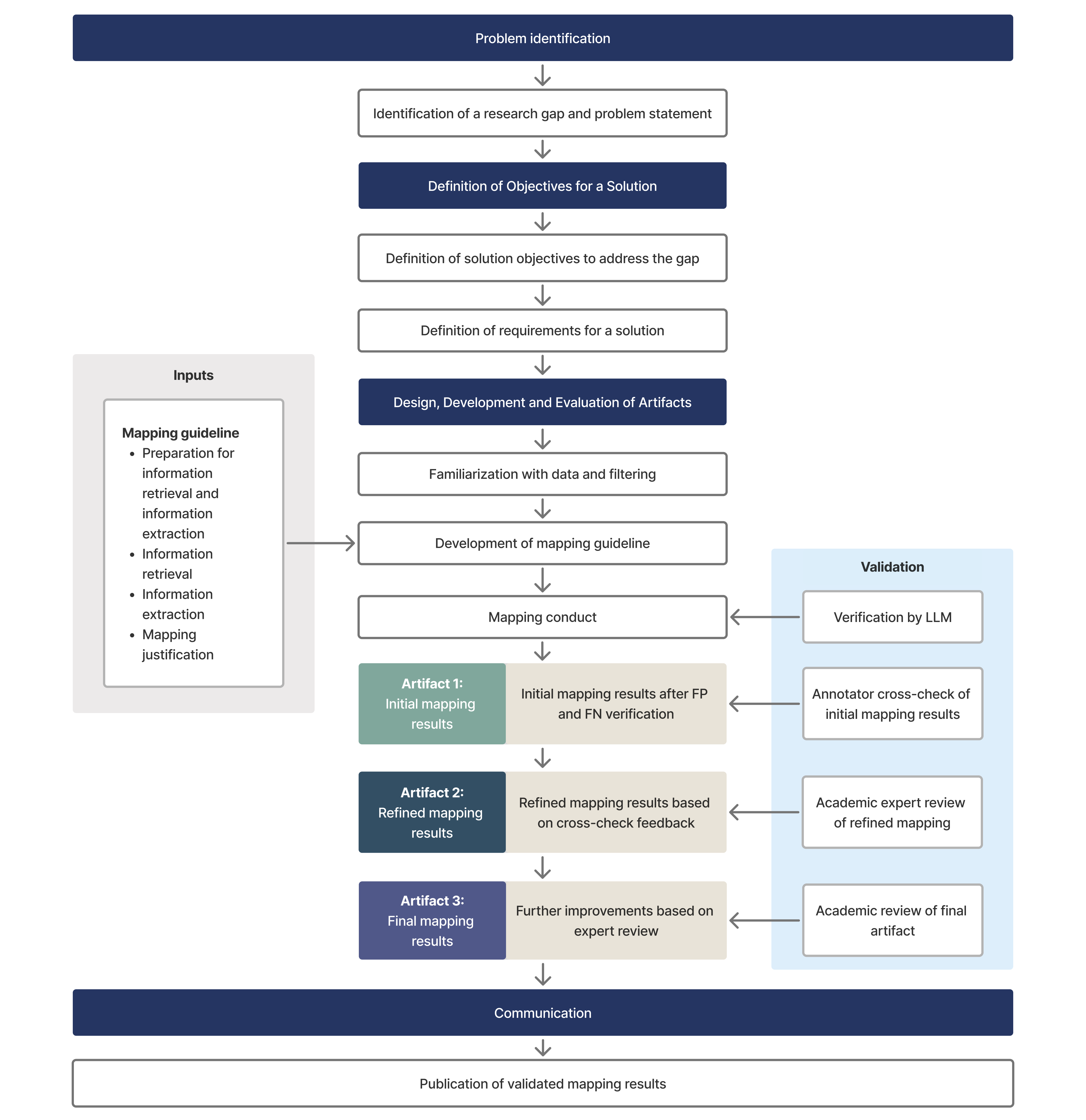
Bu tez, kullanıcıların karmaşık veri ortamlarını SQL yazmak yerine doğal dil ile sorgulayabilmesini sağlayan bir konuşma tabanlı analitik sistemi sunmaktadır. Sistem, lakehouse mimarisi üzerinde Veri Ağı (Data Mesh) ve Veri Dokusu (Data Fabric) ilkelerini birleştirmekte ve veri kümelerini keşfetmek, metadatayı zenginleştirmek ve tablolar arası ilişkileri çıkarsamak için LLM tabanlı ajanlar kullanmaktadır. Amaç, metadatanın şeffaf, yeniden kullanılabilir ve yeniden üretilebilir kalmasını sağlarken veri keşfi ve şema incelemesi için gereken manuel eforu azaltmaktır. Yaklaşım, ilişki metadatasının sorgu doğruluğu ve yeniden üretilebilirlik üzerindeki etkisini ölçmek için tasarlanmış çok alanlı bir kıyaslama üzerinden değerlendirilmiştir.
Tarih: 18.06.2026 / 15:00 Yer: A-212
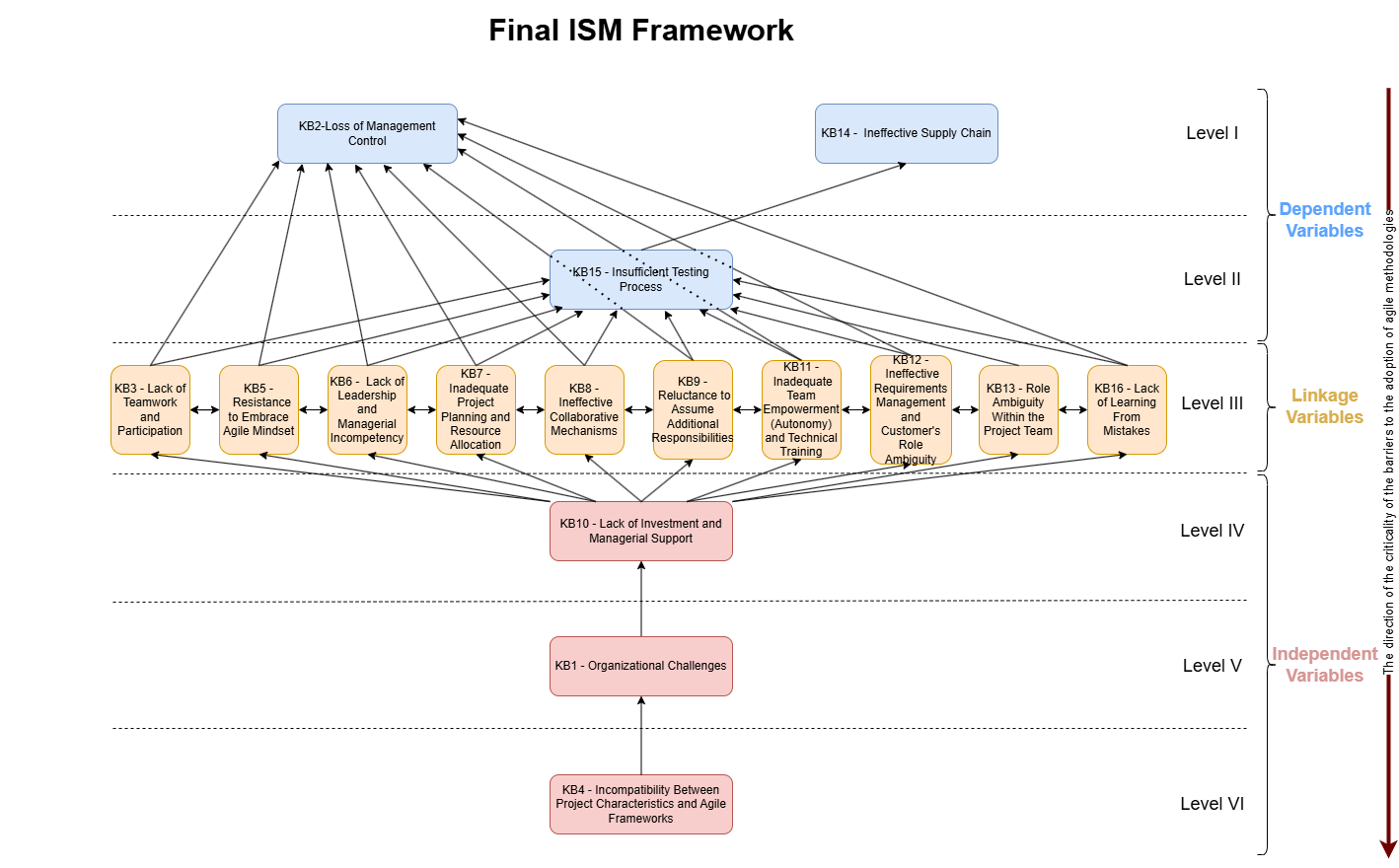
Bu çalışma, Türkiye savunma sanayiinde çevik metodolojilerin benimsenmesinin önündeki kritik bariyerleri belirlemekte ve incelemektedir. Kapsamlı bir literatür taraması ve uzman görüşlerinden yararlanan araştırma, esnek ve iş birliğine dayalı metodolojilere geçişteki temel zorlukları belirlemektedir. Anket verilerine Yorumlamalı Yapısal Modelleme (ISM) ve MICMAC yaklaşımlarını uygulayan bu çalışma, bariyerler arasındaki nedensel ilişkileri ve karşılıklı bağımlılıkları haritalandırarak katmanlı, hiyerarşik bir çerçeve oluşturmaktadır. Nihayetinde bu araştırma, savunma sanayii yöneticilerine farkındalığı artırmak, benimseme engellerini hafifletmek ve başarılı bir çevik dönüşüm için sağlam bir zemin hazırlamak amacıyla sistematik bir anlayış ve kapsamlı bir çerçeve sunmaktadır.
Tarih: 17.06.2026 Yer: A-212
Bu çalışma, erken replike olan genlere daha yüksek skorlar atayarak, farklı hücre hatlarındaki protein kodlayan genlerin replikasyon zamanlamasını SigProfilerTopography kullanarak nicel bir şekilde inceliyor. Aslında ilk başta doğrudan replikasyon zamanlamasını tahmin eden bir model kurmayı hedeflemiştik; ancak işler beklediğimiz gibi gitmeyince, odağımızı hücre hatları arasındaki zamanlama farklılıklarını ortaya çıkarmaya çevirdik.
Tarih: 23.06.2026 / 14:30 Yer: A-212