M.S. Candidate: Deniz Kizaroğlu
Program: Data Informatics
Date: 05.01.2026 / 13:00
Place: A-212
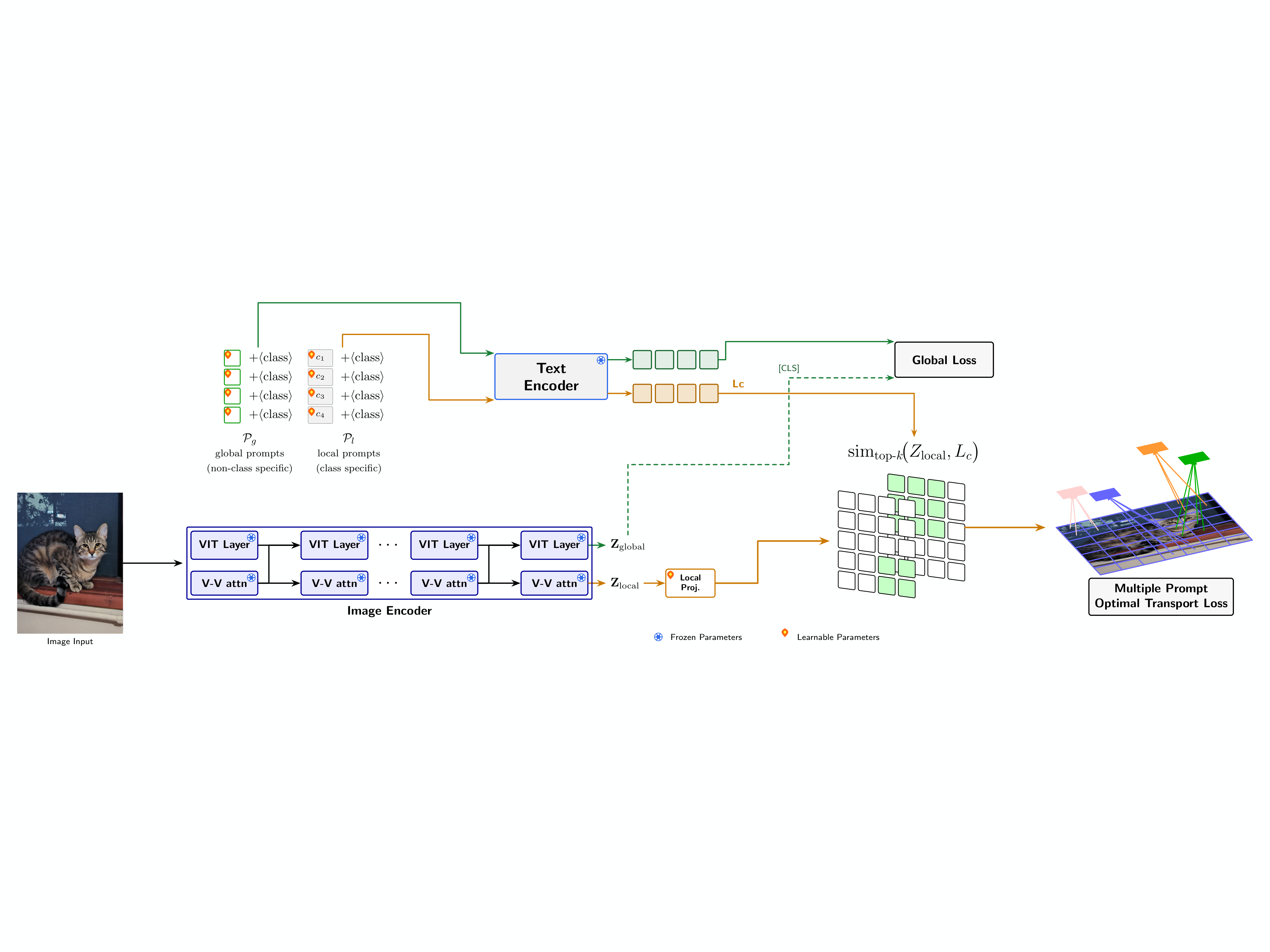
Abstract: Few-shot adaptation of large-scale vision-language models typically relies on learning soft prompts matched to holistic image embeddings. While effective for general recognition, this global approach often fails to capture the fine-grained, part-level attributes necessary for specialized tasks. In this thesis, we propose a unified framework that reconciles global semantic consistency with local discriminative alignment. Our architecture couples a standard CLIP-style global branch with a novel local pathway driven by Value–Value (V–V) attention and Optimal Transport (OT). The V–V stream extracts coherent visual structures, while the OT mechanism enforces a balanced assignment between salient image patches and class-specific local prompts, preventing the "prompt collapse" common in standard attention. Extensive evaluation on the 11-dataset few-shot benchmark (ViT-B/16) demonstrates that our method achieves a new state-of-the-art average accuracy of 85.1% (16-shot), outperforming strong baselines like GalLoP and PromptSRC. The gains are most pronounced on texture-heavy and fine-grained datasets, validating the efficacy of explicit local modeling. Furthermore, we identify a critical trade-off between specialization and robustness: while a learnable local projection maximizes in-distribution accuracy, removing it yields a highly calibrated variant that achieves state-of-the-art performance on Out-of-Distribution (OOD) detection benchmarks.