Ph.D. Candidate: Muhammet Esat Kalfaoğlu
Program: Multimedia Informatics
Date: 16.04.2026 / 14:00
Place: A-212
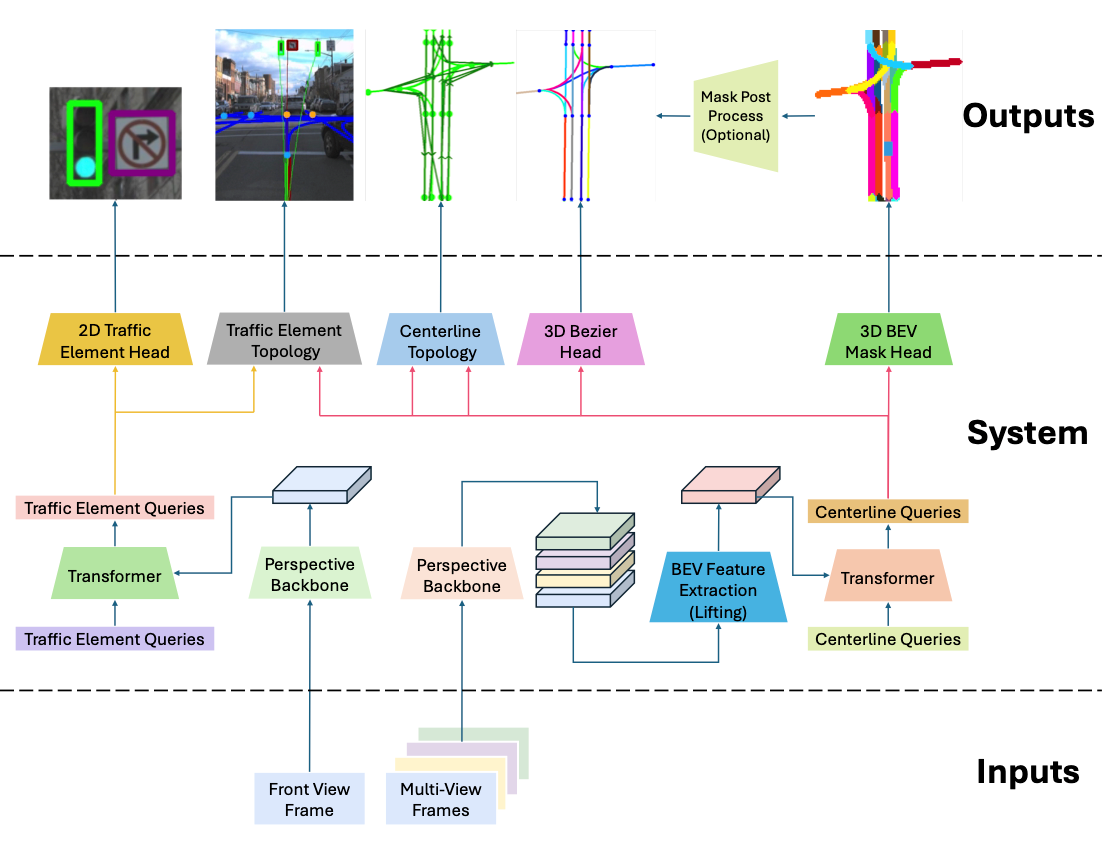
Abstract: This thesis studies transformer-based road topology understanding with centerline-centric representations and their relations to traffic elements. The core problem is to jointly model geometry and topology in complex urban scenes, where lane connectivity and lane-to-traffic-element assignments directly affect planning quality. The thesis develops three complementary phases within a common transformer-decoder formulation: (i) a mask-based modality with directional supervision and mask-Bezier output fusion, (ii) Bezier-driven decoder attention for stronger curve regression, and (iii) geographically disjoint and long-range analyses with improved generalization protocols and multimodal extensions. On the modeling side, the study introduces a mask modality as an alternative to keypoint regression or parametric regression, analyzes mask, Bezier, and fusion interactions, and shows when cross-branch auxiliary supervision improves convergence and final topology quality. For decoder design, multi-point deformable attention is adapted to Bezier-regression decoders, and Bezier Deformable Attention (BDA) is proposed to use Bezier control points directly as structured sampling guidance. The thesis also investigates hybrid matching and one-to-many auxiliary supervision for topology-aware optimization, and standardizes a score-remapping protocol to avoid threshold-induced bias in topology confidence evaluation. Experiments are conducted on OpenLane-V2 and OpenLane-V1 with consistent training and evaluation settings. On OpenLane-V2 (V1.1), camera-only performance reaches 51.7 OLS in Subset-A and 54.3 OLS in Subset-B, achieving state-of-the-art camera-only performance in both subsets under the same protocol. With multimodal fusion, OLS improves to 56.4 (camera plus LiDAR) and 58.4 (camera plus LiDAR plus SDMap) in Subset-A, and to 61.7 (camera plus LiDAR) in Subset-B. Under geographically disjoint Near-split evaluation with score remapping, the approach achieves state-of-the-art performance with 28.5 OLS-l, while mask-only and Bezier-only variants both reach 27.3 OLS-l. These results show that mask and Bezier branches are complementary, BDA is a key driver for Bezier performance, and multimodal sensing is especially beneficial in challenging and long-range settings.