Ph.D. Candidate: Ferhat Kutlu
Program: Cognitive Science
Date: 25.01.2023 / 10:00
Place: A-108
Abstract: Discourse is the level of language where linguistic units are organized in a structured and coherent way. One of the major problems in the field of discourse in particular, and NLU in general is how to build better models to sense the way constitutive units of discourse stick together to form a coherent whole. The discourse would be coherent if it had meaningful connections between its parts. Discourse relations, i.e., semantic or pragmatic relations between discourse units (clauses or sentences), are one of the most important aspects of discourse structure. Discourse relations can be realized explicitly (i.e. through connectives), or without them, known as implicit relations. The task that automatically reveals these aspects of texts has been known as ‘discourse parsing’, and in the last two decades, the problem has turned into how to make machines a better discourse detector.
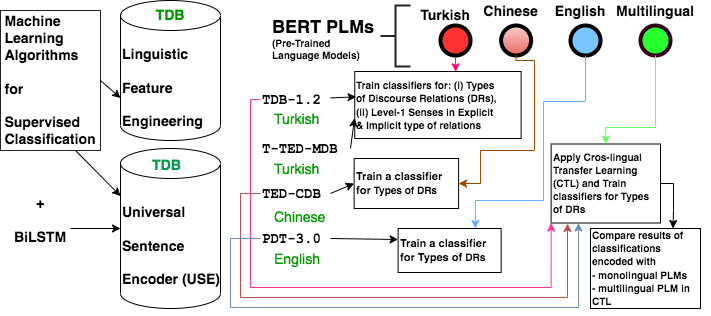
Most of the existing studies target the automatic extraction of discourse structure by detecting explicit and implicit relations and the constitutive parts of the relation (i.e., arguments). Focusing on a relatively less studied language, Turkish, this thesis is designated to reveal its discourse structure by focusing on two sub-tasks of shallow discourse parsing, namely, identification of discourse relation realization types and the sense classification of explicit and implicit relations. In this way, a better model which learns discourse structure in a supervised fashion is searched. Such models have been highly needed in the enhancement of tasks such as text summarization, dialogue systems and machine translation that need information above the clause level.
Working on Turkish Discourse Bank 1.2, the thesis develops the most thorough pipeline towards shallow discourse parsing. The series of experiments starts with a classification model based on linguistic features fed into legacy machine learning algorithms and ends with fine-tuning a pre-trained language model as an encoder and classifying the encoded data with neural network-based classifiers. Expressed in terms of F1-Scores, this effort has resulted in: (i) an increase from 0.36 to 0.77 in classifying discourse relation realization types, (ii) achieved 0.82 in the classification of the Level-1 senses of explicit relations and 0.54 of implicit relations.
The Level-2 Senses of discourse relations are so many that it becomes impossible to end up with a sound classification performance by training with the less number of samples available in the discourse bank. Thus, the study of Level-2 Senses is left to future works, potentially supported with bigger size of discourse bank.
We further explore the effect of multilingual data aggregation on the classification of discourse relation realization type through Cross-lingual Transfer Learning experiments practiced with the advantage of the BERT multilingual base model (cased) with Turkish, Chinese and English datasets. We believe that the findings are important both in providing insights regarding the performance of modern language models in Turkish and in the low-resource scenario.