Doktora Adayı: Ferhat Kutlu
EABD: Bilişsel Bilimler
Tarih: 25.01.2023 / 10:00
Yer: A-108
Özet: Söylem, dilbilimsel birimlerin yapılandırılmış ve tutarlı bir şekilde düzenlendiği dil düzeyidir. Özellikle, söylem alanındaki ve genel olarak makinanın doğal dili anlamasındaki en büyük sorunlardan biri, söylemin kurucu birimlerinin tutarlı bir bütün oluşturan yapısını algılamaya yönelik daha iyi modellerin nasıl inşa edileceğidir. Eğer parçaları arasında anlamlı bağlantılar varsa, söylem tutarlı olacaktır. Söylem bağıntıları, yani söylem birimleri (tümceler veya tümcecikler) arasındaki anlamsal veya edim bilimsel ilişkiler, söylem yapısının en önemli yönlerinden biridir. Söylem bağıntıları, açık bir şekilde (yani bağlayıcılar aracılığıyla) veya bunlar olmadan algılanabilen örtük bağıntılar olarak gerçekleştirilebilirler. Metinlerin bu yönlerini otomatik olarak ortaya çıkaran görev "söylem ayrıştırma" olarak bilinmekte olup son yirmi yılın çalışmaları, makinelerin nasıl daha iyi bir söylem algılayıcısı haline getirileceği konusuna odaklanmıştır.
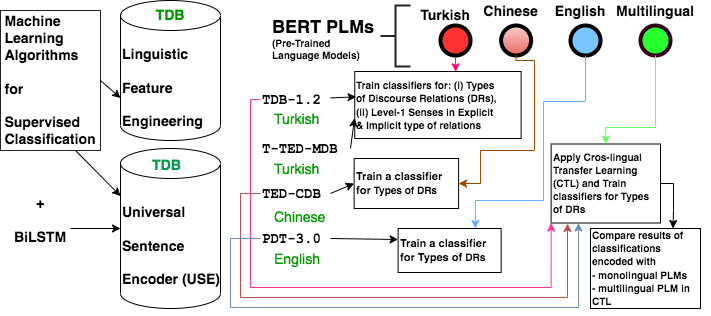
Mevcut çalışmaların çoğu, açık ve örtük bağıntıları ve bağıntının kurucu kısımlarını (yani üyelerini) tespit ederek söylem yapısının otomatik olarak çıkarılmasını hedefler. Nispeten daha az çalışılan bir dil olan Türkçe'ye odaklanan bu tez çalışması ise, sığ söylem ayrıştırması yönteminin iki alt görevine, yani söylem bağıntısı gerçekleştirme türlerinin ayrıştırılması ile açık ve örtük sınıflarının 1. Seviye anlamlarının sınıflandırmasına odaklanarak söylem yapısını tespit etmeyi amaçlamıştır. Böylece denetimli bir şekilde söylem yapısını öğrenebilen daha iyi bir modelin geliştirilmesi amaçlanmıştır. Bu tür modellere, cümle seviyesinin üzerinde bilgi gerektiren metin özetleme, diyalog sistemleri ve makine çevirisi gibi görevlerin geliştirilmesinde oldukça ihtiyaç duyulmaktadır.
Türkçe Söylem Bankası 1.2 versiyonu üzerinde gerçekleştirilen tez çalışması, sığ söylem çözümlemesine yönelik mevcut teknoloji ile olabilecek en yüksek faydayı sağlayan bir sistemin bileşenlerini hayata geçirmeye yöneliktir. Dilbilimsel özelliklerden faydalanılarak çıkarılan verinin, klasik makine öğrenimi algoritmalarıyla sınıflandırılmasına yönelik model geliştirilmesiyle başlayan bu tez çalışması, önceden eğitilmiş bir dil modelinin göreve yönelik tadil edilmesi ve sayısallaştırılmış verinin sinir ağı tabanlı sınıflandırıcılarla ayrıştırılabilmesi ile sona ermiştir. Sınıflandırma deney sonuçlarını F1-Puanları cinsinden ifade edersek, tez çalışmasında geliştirilen modeller: (i) söylem bağıntısı gerçekleşme tiplerini 0,36'dan başlayıp 0,77'ye yükselen bir başarı ile sınıflandırabilmiş, (ii) açık ve örtük sınıflarının 1. Seviye anlamları için sırasıyla 0,82 ve 0,54 başarı ile sınıflandırabilmiştir.
Söylem bağıntısı tiplerinin 2. Seviye anlamlarının sınıflandırılması gereken kategori sayısını yüksek bir düzeye çıkardığı için, Türkçe Söylem Bankasında bulunan işaretleme sayısı ile sağlıklı bir sınıflandırma performansı elde etmenin imkânsız olduğu görülmüştür.
Çalışmada son olarak, değişik dillerin veri kümeleri birleştirilerek söylem bağıntısı türlerinin sınıflandırılması üzerindeki etkisi araştırılmış, bu amaçla Türkçe, Çince ve İngilizce veri kümelerinin BERT (büyük küçük harf duyarlı) çok dilli temel modeli ile Diller Arası Transfer Öğrenme deneyleri gerçekleştirilmiştir. Bulguların, modern dil modellerinin Türkçe gibi az kaynaklı diller üzerinde yapılacak çalışmaların performansına etkilerine ilişkin fikir vermesi açısından önemli olduğu değerlendirilmektedir.