











Announcements
Research News
This thesis presents a systematic evaluation of Static Application Security Testing (SAST) tools. Related studies mostly use synthetic codebases and per-vulnerability evaluation methods. In this study, both synthetic benchmarks and real-world intentionally vulnerable applications are tested against tools, along with per-issue evaluation. Conducted experiments measure various metrics and explain these results with reasons behind them. In addition to quantitative results, qualitative features and internal mechanisms of tools are examined to further explain results and observed performance differences. The results demonstrate the difference between evaluation models and tool effectivenes. Overall, thesis offers practical insights for SAST tool research and selection.
Date: 14.04.2026 / 11:00 Place: Cisco Lab

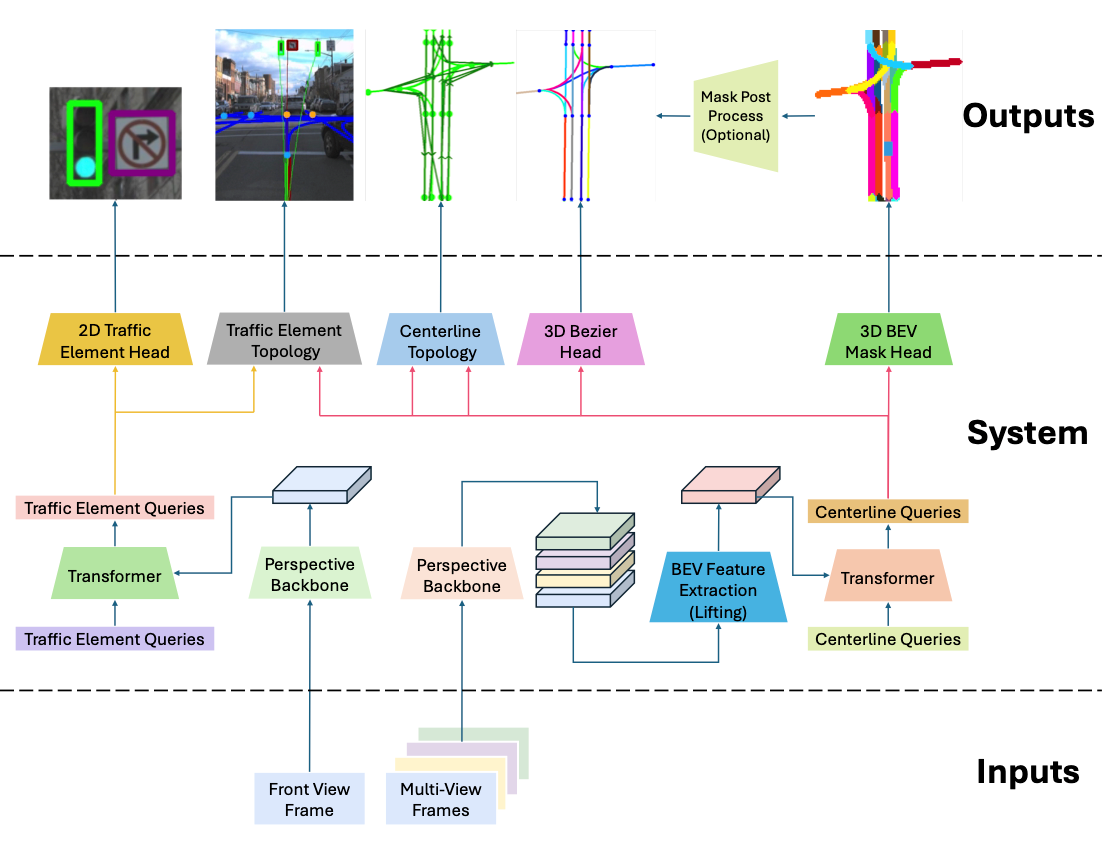
This thesis studies multi-view, multimodal BEV perception for centerline-centric road topology understanding in autonomous driving. It focuses on improving centerline detection within a transformer-decoder framework and examines how those gains propagate to topology reasoning. The work develops three stages: mask-based centerline prediction with directional supervision and mask-Bezier fusion, Bezier-driven decoder attention through multi-point and Bezier deformable attention, and geographically disjoint plus long-range multimodal evaluation. Experiments on OpenLane-V2 and OpenLane-V1 show strong camera-only and fused camera-LiDAR performance, supporting state-of-the-art road topology understanding under consistent protocols.
Date: 16.04.2026 / 14:00 Place: A-212
Somatic mutations drive the transformation of normal cells into cancer. However,distinguishing driver mutations, which confer a selective growth advantage, from the vast background of neutral passenger mutations remains a critical challenge. To address this, we introduce a novel graph-based framework that constructs mutation-centric networks by leveraging longrange genomic interaction data. Our method models genomic intervals as nodes and their long-range interactions or overlaps as edges. Starting from a ’seed’ mutation, the graph expands iteratively, finding overlaps and interacting intervals to capture both local and distal genomic context. This architecture allows us to quantify a mutation’s topological influence, identify complex structural patterns (such as graph cycles), and assess proximity to known driver genes across variable ranges. Furthermore, this approach naturally generates embeddings for individual mutations, enabling the clustering of samples based on mutation profile similarity. Ultimately, by providing a comprehensive, interaction-aware view of the genomic landscape, our framework facilitates more accurate driver identification and improved patient stratification for personalized treatment.
Date: 13.04.2026 / 14:00 Place: B-116

This thesis presents an empirical investigation into the impact of Large Language Model (LLM) assistance on the human factors of software practitioners. Through a controlled within-subject experiment conducted with 30 practitioners, the study compares conditions with and without LLM support using a software requirements specification task. The research utilizes validated psychometric scales and semi-structured interviews to analyze four key dimensions: perceived task complexity, motivation, sense of achievement, and creative self-efficacy. The study provides structured empirical evidence on how LLM tools shape cognitive and psychological processes beyond technical productivity.
Date: 03.04.2026 / 14:30 Place: A-212

This thesis aims to improve demand forecast accuracy through the implementation of machine learning/deep learning applications. SARIMA, LSTM, CNN, and Prophet models are implemented to forecast demand. The models are trained and validated using forward-chaining cross validation method. It applies time series forecasting on a seasonal, unbalanced and intermittent dataset. The effects of selected exogenous indicators and aggregation-disaggregation approaches are examined for further improvement.
Date: 20.01.2026 / 14:30 Place: A-212
