M.S. Candidate: Melek Ertan
Program: Cognitive Science
Date: 27.01.2023 / 15:00
Place: A-212
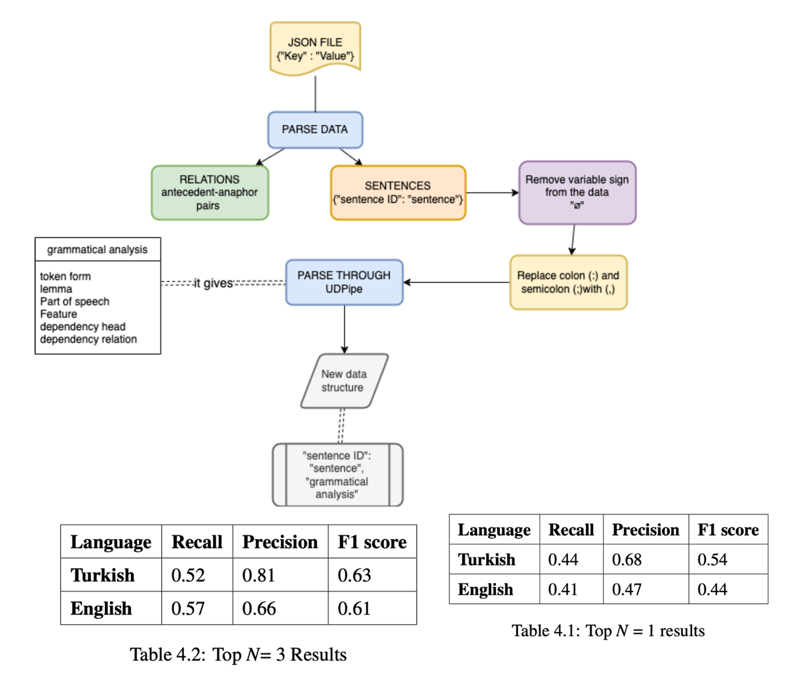
Abstract: This research analyzes pronominal anaphora in a Turkish and English translated TED corpus, namely the TED-MDB (Zeyrek et al., 2020) and presents a heuristic-based resolution algorithm for resolving pronominal anaphora in these languages separately. The corpus has characteristics of spoken language and has 364 English sentences aligned with their Turkish counterparts. The research is divided into two stages. In the first stage, the data was annotated using a web-based annotation tool INcePTION (Klie et al., 2018). The second phase of the study involves a computational analysis, where the traditional knowledge poor algorithm by Mitkov (1998) was tested on the annotated corpus for Turkish and English separately. The results showed that pronom- inal anaphora can be detected in TED talks with an F1-score of 0.61 in English, and with 0.63 in their Turkish translations.use of directed acyclic graphs to graphically represent counterfactual scenarios in Turkish.