M.S. Candidate: Toyan Ünal
Program: Information Systems
Date: 07.12.2023
Place: A-212
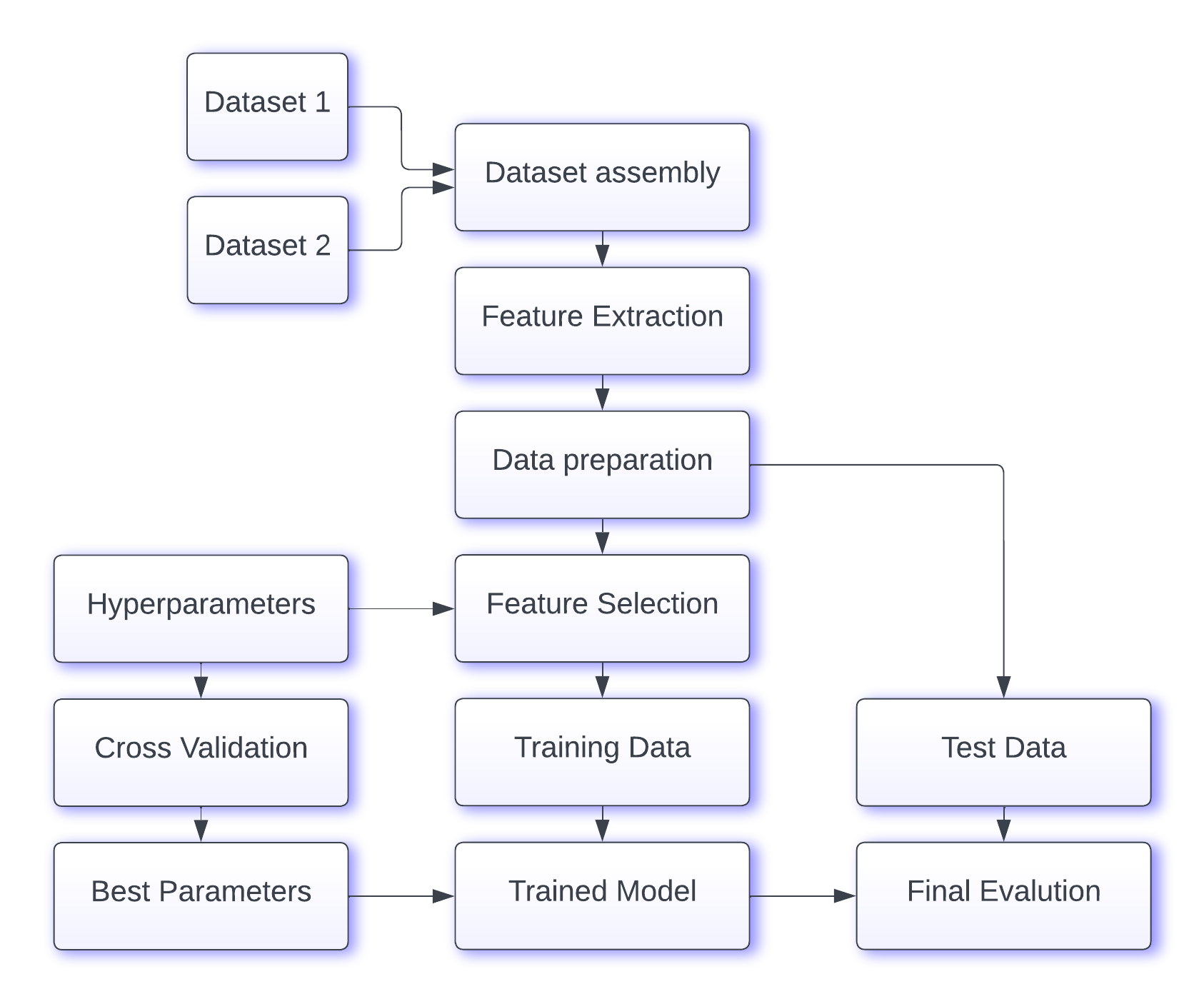
Abstract: Machine learning methods are effective for forecasting tennis match results, but the empirical nature of these methods means that specific decisions about datasets, models, feature sets, or hyperparameters can significantly affect outcomes. This thesis uses the Sports Result Prediction Cross-Industry Standard Process for Data Mining experimental framework to ensure results are replicable and reproducible across various datasets and sports types. It includes 14 years of men’s singles tennis match data from 2009 to 2022, reserving data from the last two years as a hold-out test set. We employed six advanced feature extraction techniques, three machine learning models, and two feature selection methods, with a 10-fold time-based cross-validation and hyperparameter tuning. The Extreme Gradient Boosting model proved the most effective, achieving a Brier score of 0.1913 and 70.5% accuracy on the test set, with average win ratios implied by bookmakers’ odds being the most predictive feature.