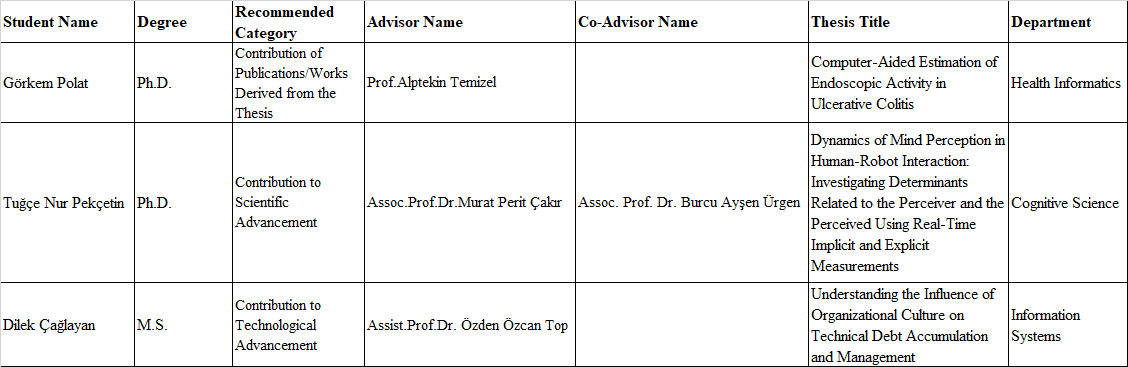
Rabia Nur Gevrek, Cost-Driven Predictive Maintenance Strategy Based on Varying Prediction Horizons
This thesis proposes a cost-driven predictive maintenance strategy for turbofan engines using the C-MAPSS dataset. The method predicts failures within multiple horizons using LSTM models, interprets predictions via SHAP analysis, and applies maintenance decisions based on dominant sensor contributions. Various maintenance and failure cost ratios are evaluated, and strategies are compared to identify the most cost-effective approach. Results provide decision-making insights for companies with different cost priorities and operational constraints.
Date: 25.08.2025 / 15:30 Place: A-212
English