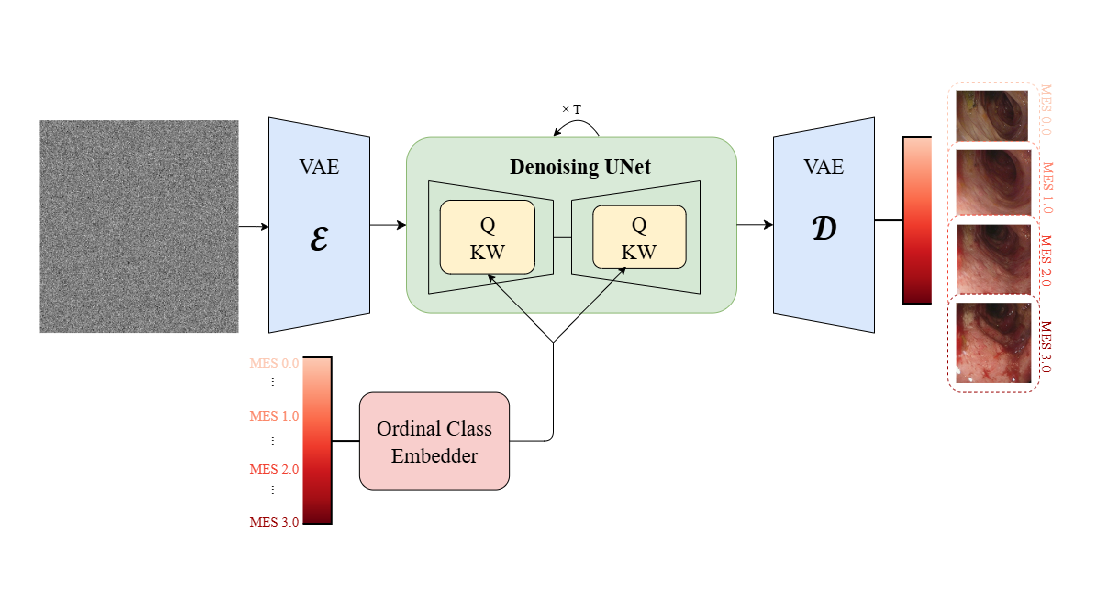
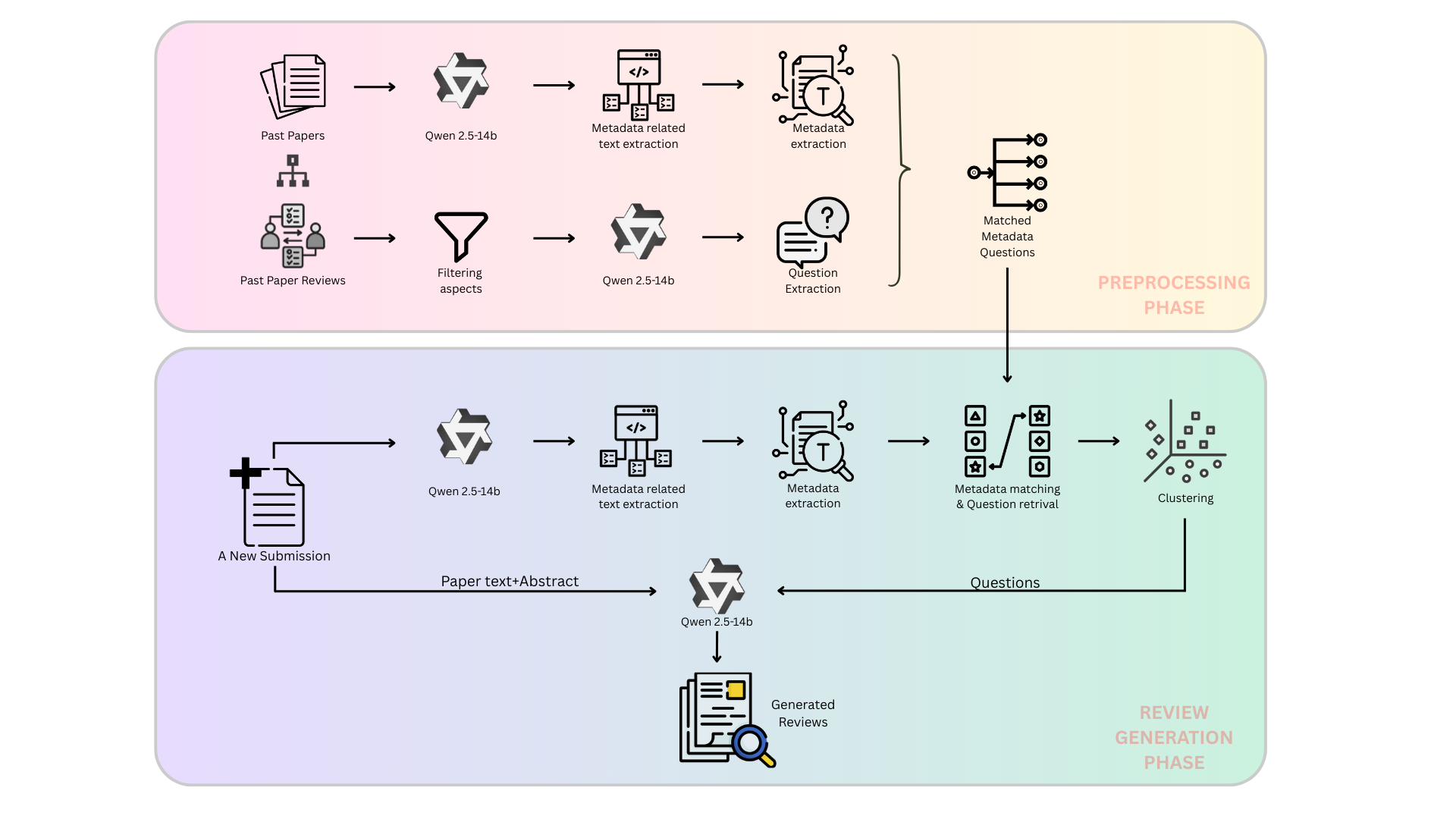
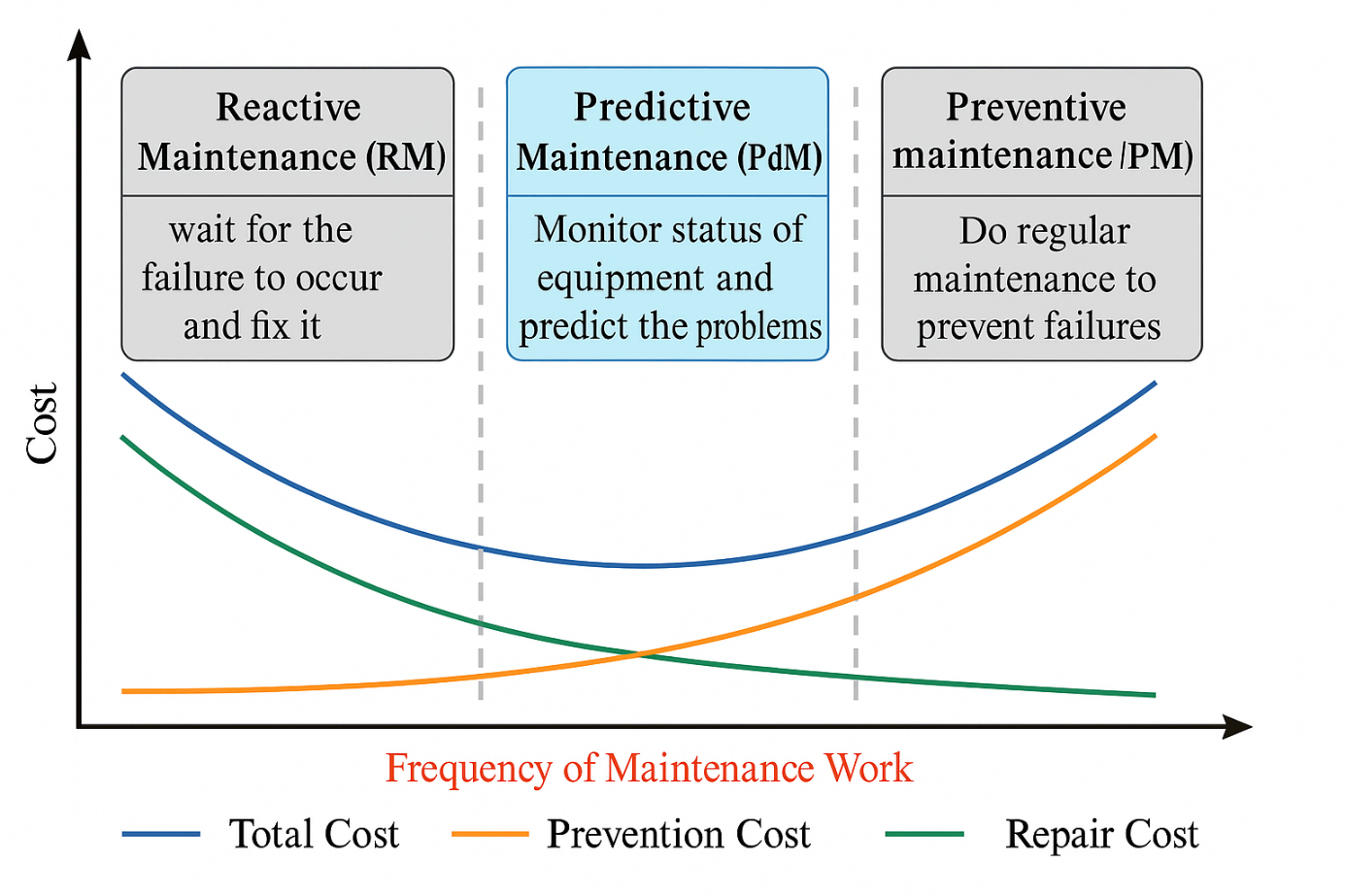
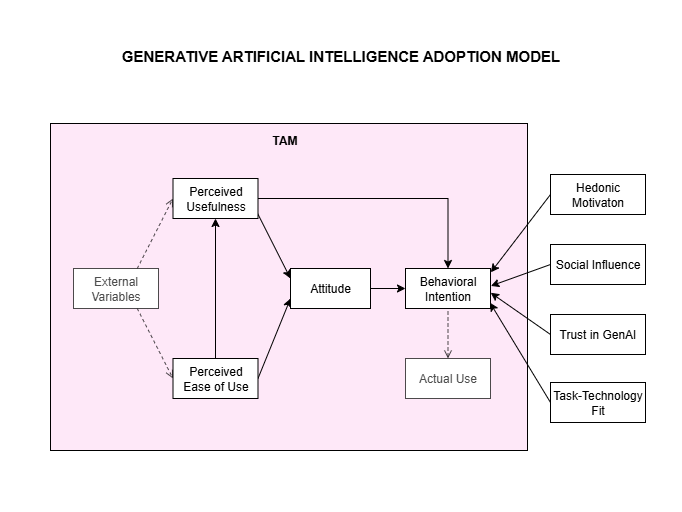
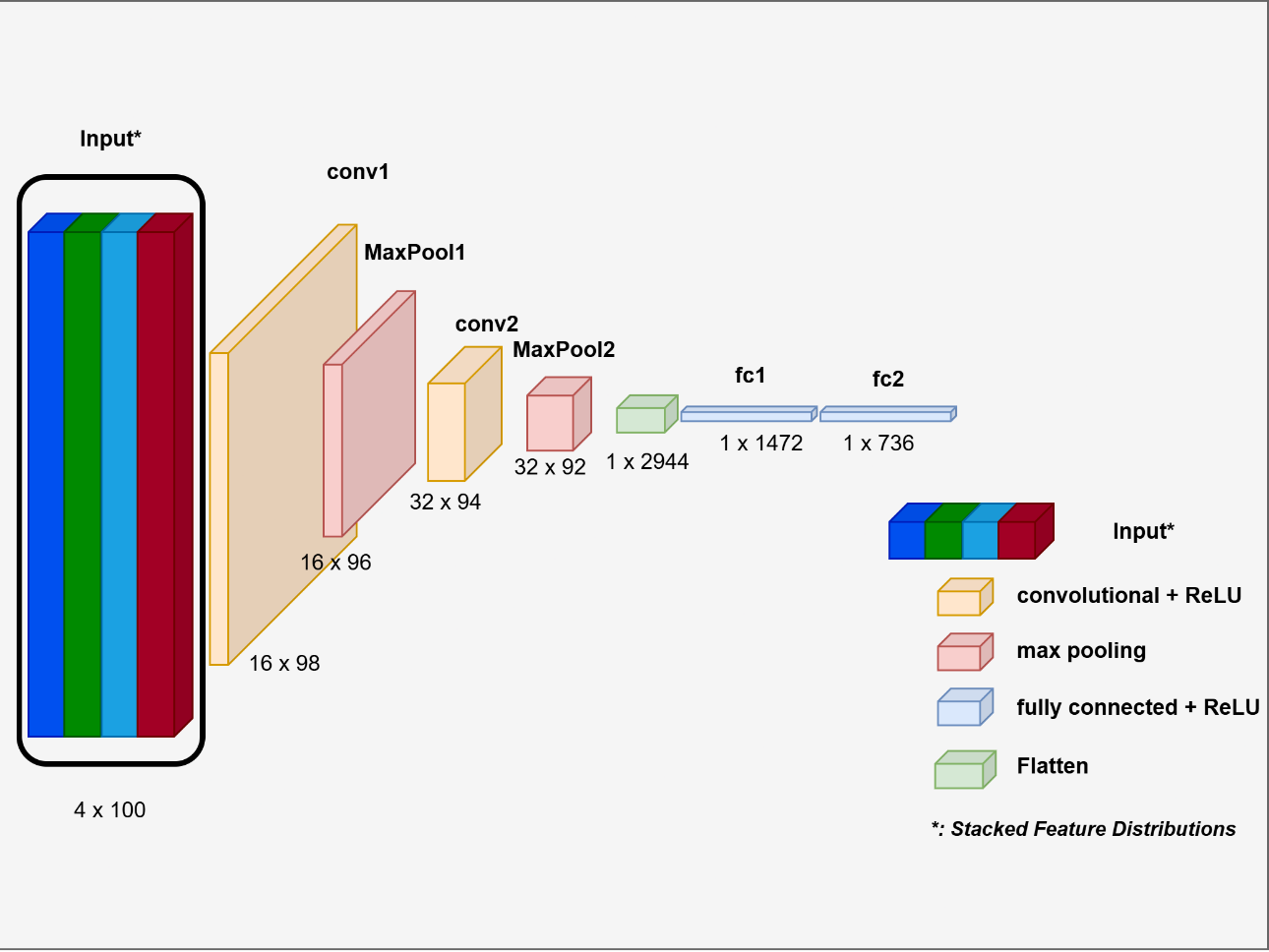
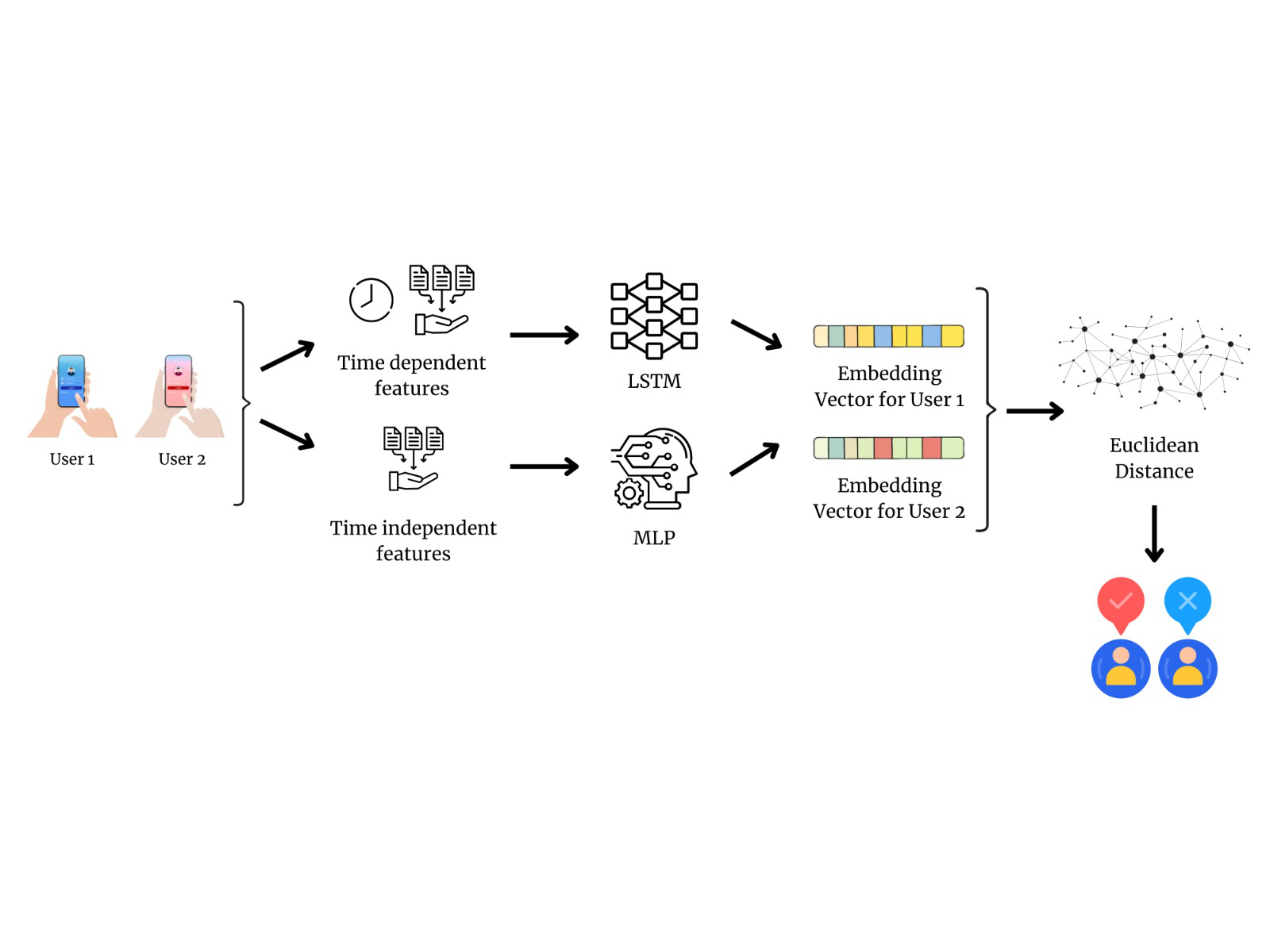
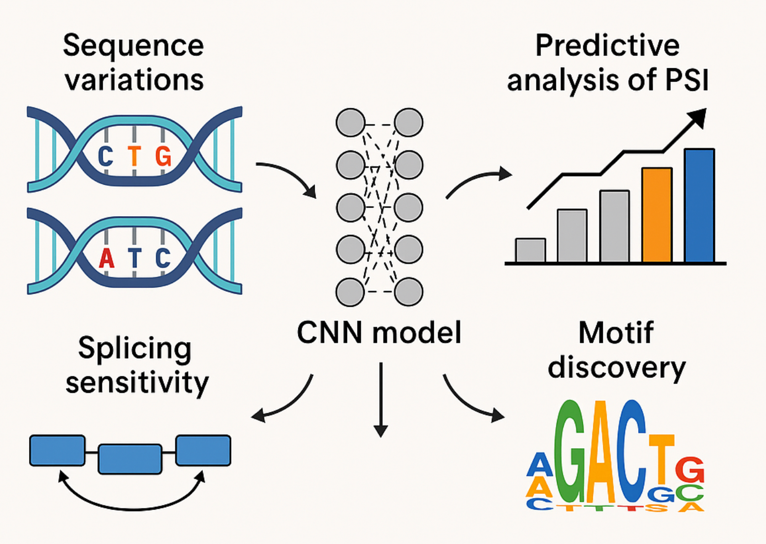
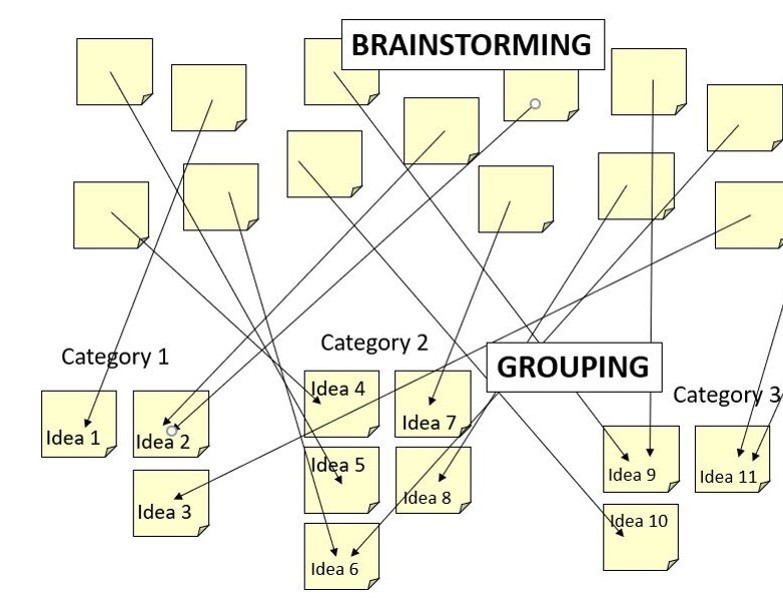
Ant Duru, Dataset Adaptive Data Augmentation for Object Detection
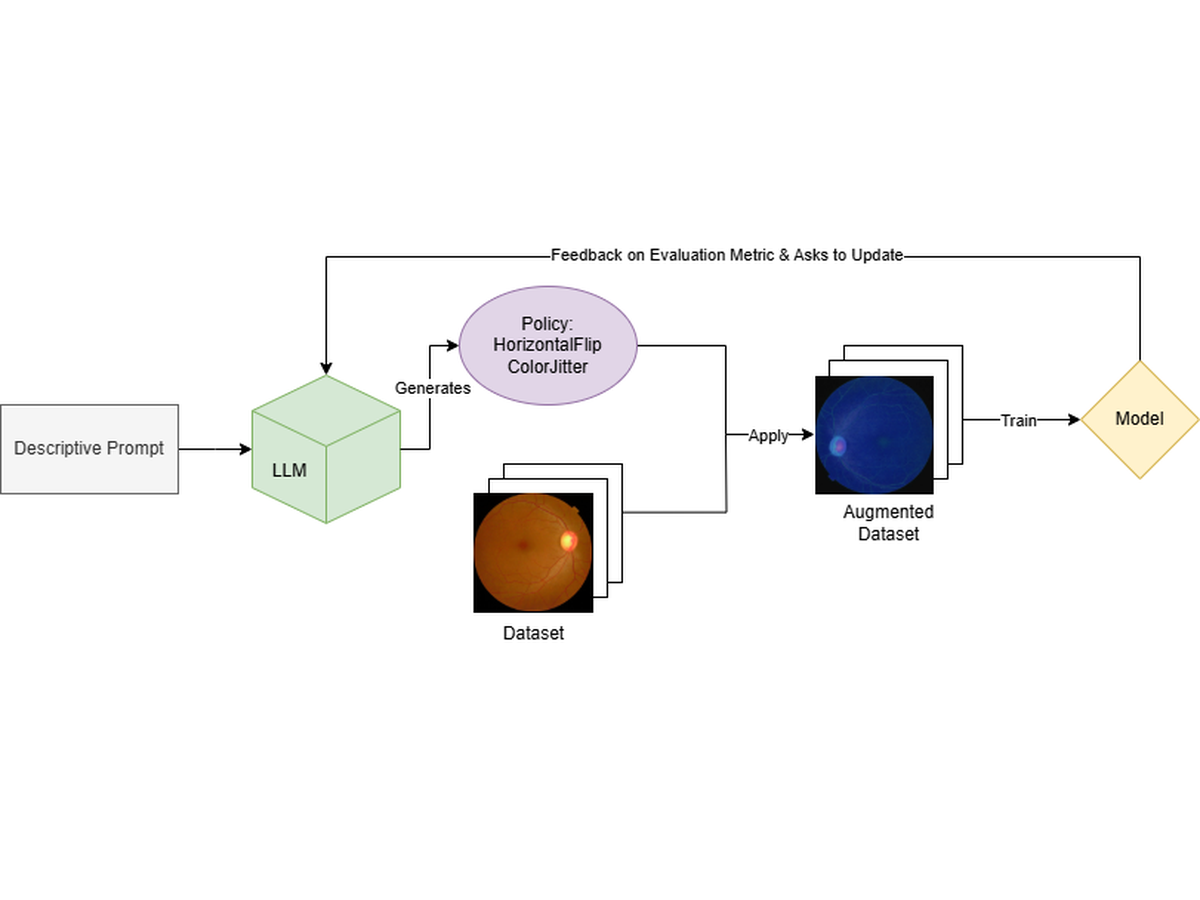
This thesis introduces a Large Language Model (LLM)-driven framework for automated augmentation policy optimization in image classification. The approach leverages LLM reasoning to generate and adapt augmentation strategies without human intervention. Two modes are explore: a before-training method that iteratively refines static LLM-generated policies, and an in-training adaptive method where policies evolve based on real-time performance feedback. By integrating semantic understanding with optimization loops, the framework tailors augmentation to dataset characteristics, enhancing model robustness and generalization compared to conventional augmentation techniques.
Date: 28.08.2025 / 14:45 Place: B-223
English