Yüksek Lisans Adayı: Övgü Özdemir
EABD: Çokluortam Bilişimi
Tarih: 04.09.2024 / 13:30
Yer: A-212
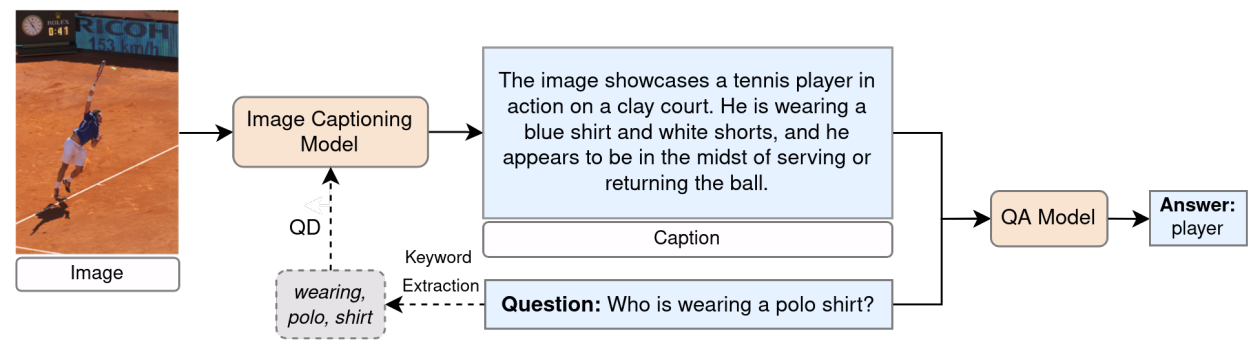
Özet: Görsel soru cevaplama (VQA), bir görsele dayanarak doğal dildeki sorulara doğal dilde yanıtların verildiği yapay zeka görevini ifade eder. Çok modlu işlemeyi gerektirmesinden dolayı VQA zorlu bir problemdir. VQA, sıklıkla görseldeki sahneyi anlamayı, nesneler ve nitelikler arasındaki ilişkiyi çıkarmayı ve çok adımlı muhakeme yapmayı gerektirir. Geçtiğimiz yıllar boyunca, VQA için pek çok farklı derin öğrenme yapısı önerilmiştir. Son yıllarda ise önceden eğitilmiş görsel-dil modelleri ve milyarlarca parametreli çok modlu büyük dil modelleri (MLLM) değerlendirmelerde üstün performans göstermektedir. Buna rağmen, sıfır-atış VQA'de hala performans iyileştirmek için boşluklar vardır. Sıfır-atış VQA, girdi-çıktı rehberliği olmadan göreve adapte olmayı ve bunun için de gelişmiş muhakeme yeteneği gerektirir. Bu nedenle, son yıllarda araştırmalar, MLLM'ler için muhakemeyi ortaya çıkaracak istem tasarımlarına yoğunlaşmıştır. Bu tez, LLM'leri kullanarak ve bağlama duyarlı görüntü altyazılamayı ara bir adım olarak entegre ederek, sıfır-atış VQA'deki performansı artırmayı amaçlayan yeni bir yaklaşım önermektedir. CogVLM, GPT-4 ve GPT-4o gibi yeni MLLM'ler kullanılarak yapısal ve anlamsal açıdan çeşitli sorular içeren ve genellikle çok adımlı muhakeme gerektiren GQA test seti üzerinde değerlendirme ve karşılaştırma yapılmıştır. Ayrıca, tez, farklı prompt tasarımlarının VQA performansına etkisini incelemektedir. Bulgular, sıfır-atış ayarlarında VQA performansını artırmak için görüntü açıklamalarının ve optimize edilmiş istemlerin kullanım potansiyelini vurgulamaktadır.