Umut Güler, Yapay Zeka Tarafından Üretilen Ön Uç Kod Kalitesinin Değerlendirilmesi: Karşılaştırmalı Bir Çalışma
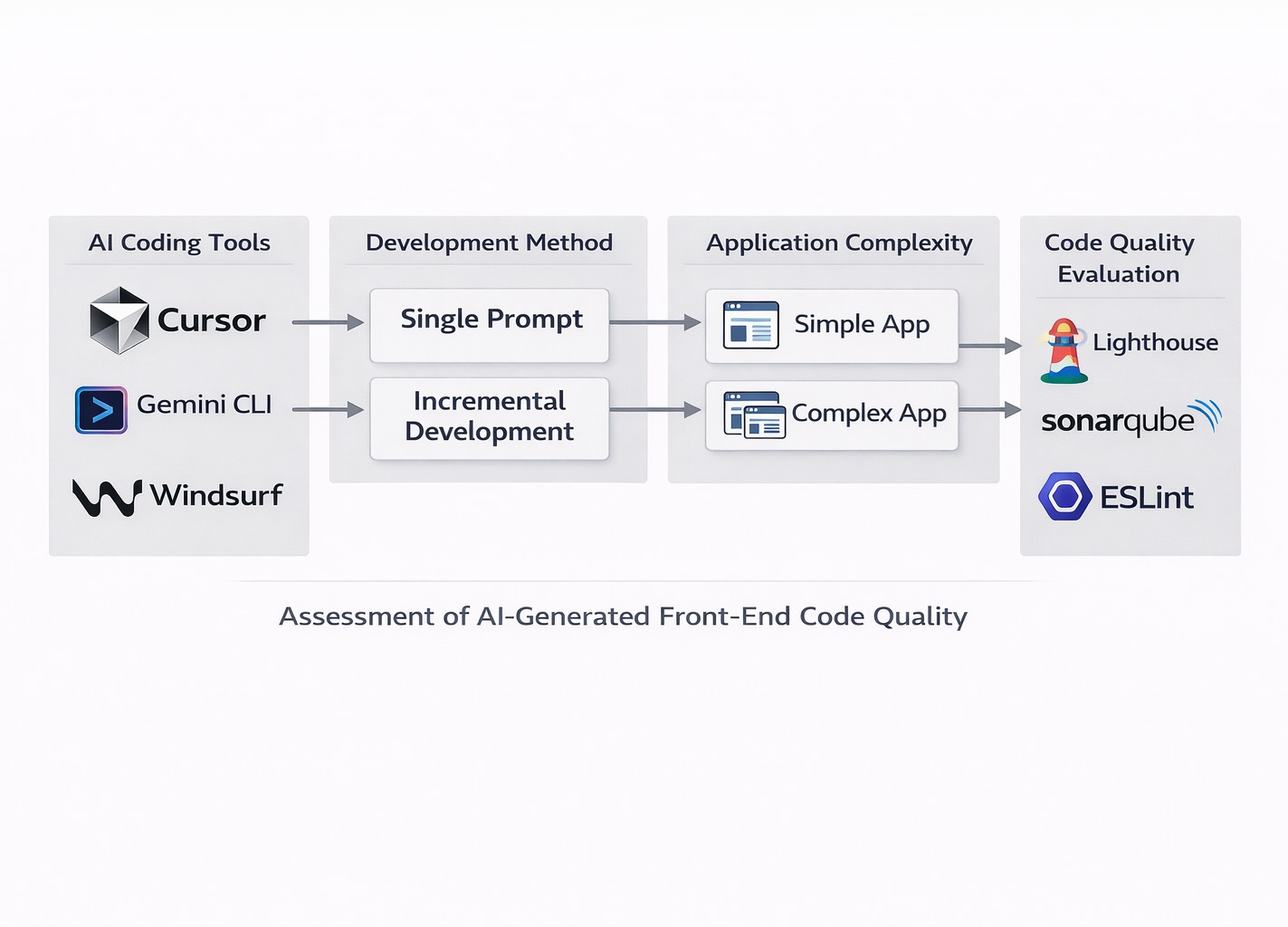
Bu tez, yapay zeka tarafından üretilen ön uç kod kalitesinin karşılaştırmalı ampirik bir değerlendirmesini sunmaktadır. Üç çağdaş yapay zeka kodlama aracı—Cursor, Gemini CLI ve Windsurf—çeşitli karmaşıklıkta React ve TypeScript uygulamalarını içeren kontrollü deneyler yoluyla değerlendirilmiştir. Çalışma, Lighthouse, SonarQube ve ESLint dahil olmak üzere endüstri standardı ölçütler kullanılarak hem tek komutlu hem de artımlı geliştirme yaklaşımlarını değerlendirmektedir. Bulgular, yapay zeka araçlarının işlevsel olarak doğru uygulamalar üretebildiğini, ancak kod kalitesi sonuçlarının araç seçimine, geliştirme metodolojisine ve uygulama karmaşıklığına bağlı olarak önemli ölçüde değiştiğini göstermektedir. Sonuçlar, modern ön uç geliştirmede yapay zeka araçları ve iş akışlarının seçimi için kanıta dayalı bir rehber sağlamaktadır.
Tarih: 20.01.2026 / 13:00 Yer: A-212